

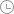

OCR ( Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。
 当需要将纸质文档扫描并创建成电子文档或对现有的电子文档(如 PDF文档或 PDF 文件包)进行操作时, OCR 是最常用的一种方式。
当需要将纸质文档扫描并创建成电子文档或对现有的电子文档(如 PDF文档或 PDF 文件包)进行操作时, OCR 是最常用的一种方式。
在日常工作学习中,当使用福昕高级PDF编辑器打开基于纸质扫描或图片的PDF文档时,能自动检测到并弹出以下信息框,提示是否进行 OCR。
对于 PDF中基于图像的文本,我们可以随时对其执行文本识别操作~
打开福昕高级PDF编辑器,点击“转换” > “识别文本” > “当前文件”, 在弹出的“识别文本”对话框中,指定识别范围。从语言列表中选择文档的语言,您也可以选择多种语言。
若勾选“可检索文件的图像”,则识别后图片上的文本可以被选择并且您在检索文本时可搜索到文档中图片上的文本;若勾选“可编辑文本”,则识别后编辑文本时图片上的文本也可支持编辑。 点击“确定”开始识别文本。PDF文本识别进程条将会弹出显示进程,识别结束后,再执行搜索功能,您会发现原来在图片上或扫描文档中的文本也可以被搜索到。
点击“确定”开始识别文本。PDF文本识别进程条将会弹出显示进程,识别结束后,再执行搜索功能,您会发现原来在图片上或扫描文档中的文本也可以被搜索到。
(1)可检索文件的图像:在 OCR过程中,程序将对图片上文本进行分析并使用与这些文本非常接近的字词替代图片上的文本。
替代的字词将被放置在 PDF中一个不可见的文本层上, 从而使图片上的文本可以被选择和搜索。
替代过程中程序无法确定的文本将被标记为 OCR 疑似错误结果,并需要手动进行更正。
(2)可编辑文本:在OCR过程中, 程序对图片上的文本的形状与系统上安装的近似字体进行比对后,将这些文本转换为可编辑文本。
在日常工作学习中,当使用福昕高级PDF编辑器打开基于纸质扫描或图片的PDF文档时,能自动检测到并弹出以下信息框,提示是否进行 OCR。
对于 PDF中基于图像的文本,我们可以随时对其执行文本识别操作~
打开福昕高级PDF编辑器,点击“转换” > “识别文本” > “当前文件”, 在弹出的“识别文本”对话框中,指定识别范围。从语言列表中选择文档的语言,您也可以选择多种语言。
若勾选“可检索文件的图像”,则识别后图片上的文本可以被选择并且您在检索文本时可搜索到文档中图片上的文本;若勾选“可编辑文本”,则识别后编辑文本时图片上的文本也可支持编辑。
(1)可检索文件的图像:在 OCR过程中,程序将对图片上文本进行分析并使用与这些文本非常接近的字词替代图片上的文本。
替代的字词将被放置在 PDF中一个不可见的文本层上, 从而使图片上的文本可以被选择和搜索。
替代过程中程序无法确定的文本将被标记为 OCR 疑似错误结果,并需要手动进行更正。
(2)可编辑文本:在OCR过程中, 程序对图片上的文本的形状与系统上安装的近似字体进行比对后,将这些文本转换为可编辑文本。

