









扫一扫添加福昕福利官

MAC版PDF转成Excel时乱码如何处理? 若表单为PDF格式要直接进行编辑的话,肯定没有Excel来的方便。 但当我们将PDF转到excel中时,打开excel,却发现数据在其中已经消失,变成一堆乱码而无法使用。 那么, PDF转Excel乱码的原因有哪些以及改该如何解决呢? 实际上PDF转成Excel乱码的原因多种多样,但出现频率比较高的原因之一就是原来的PDF文档是扫描件的问题,这样,实际上我们看PDF中似乎只是表单,然而它的一幅图。 若要将PDF切换到Excel中进行正常切换,可先使用PDF对ocr文本进行编辑识别,然后再将新建PDF切换到excel中,以下就是具体的操作流程。

推荐工具:点击下载【福昕PDF编辑器MAC版】
1、首先大家在本站下载【福昕PDF编辑器】,完成安装后打开,把需要进行OCR文字识别的PDF文件准备好,然后导入。
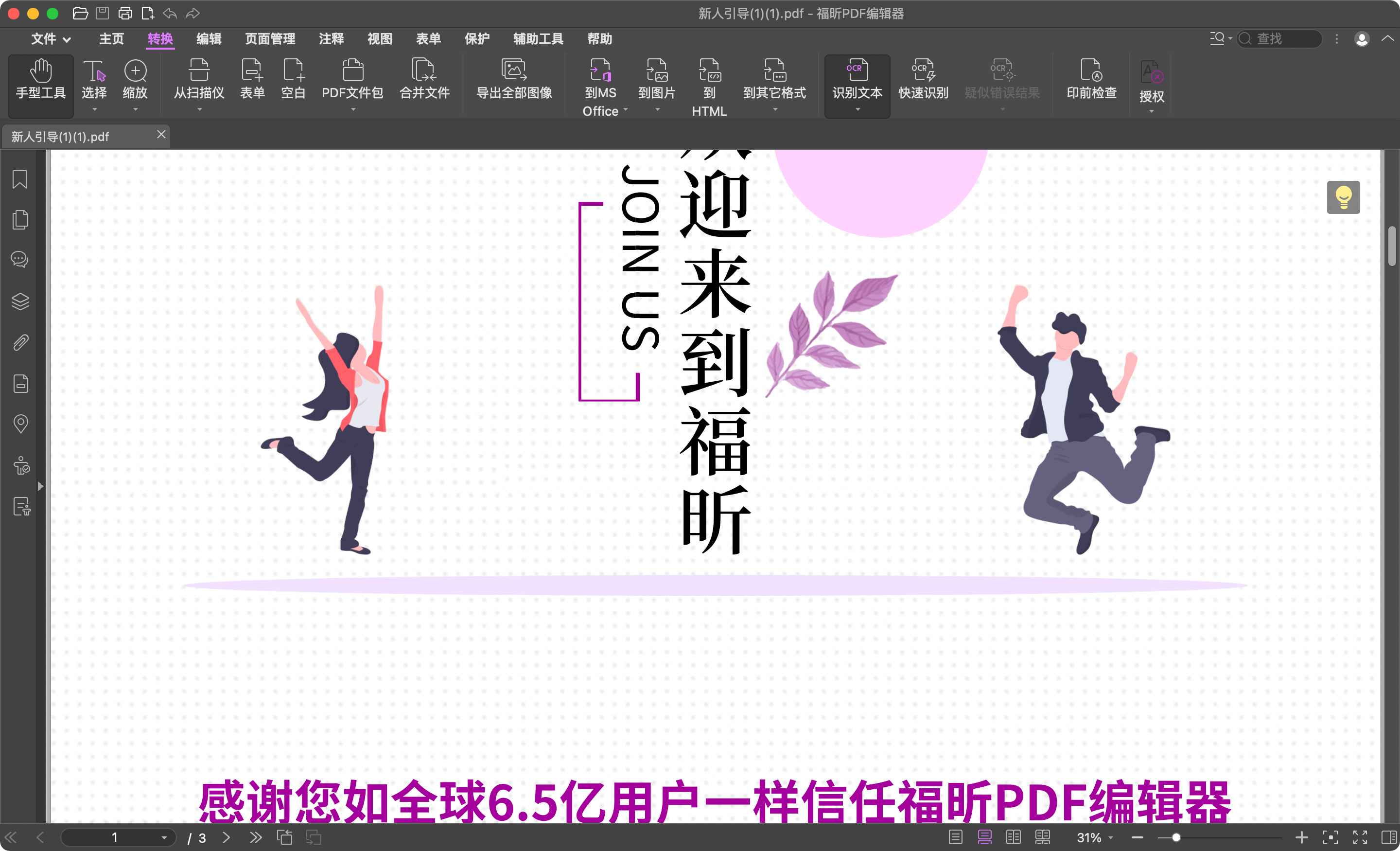
2、完成第一步之后,我们找到顶部的【OCR文字识别】功能。
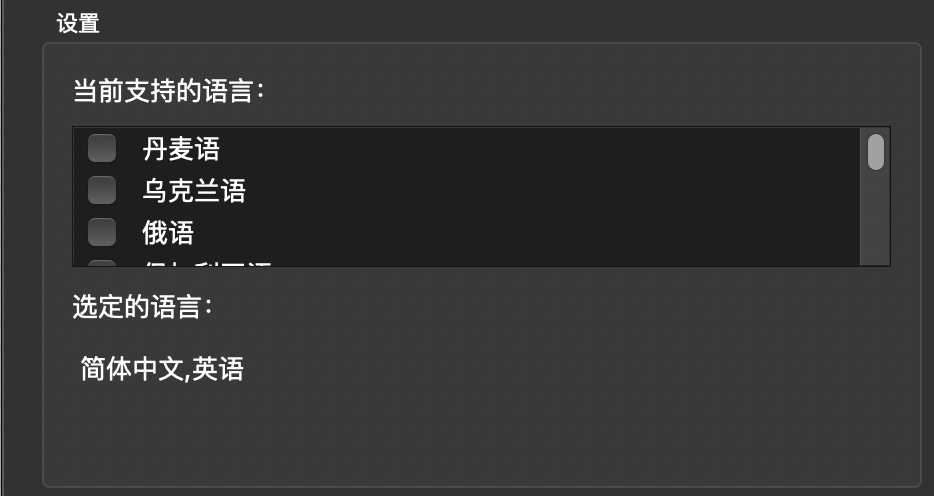
3、在弹窗中选择所需要识别的语言,当前选定的语言为"简体中文,英文"。
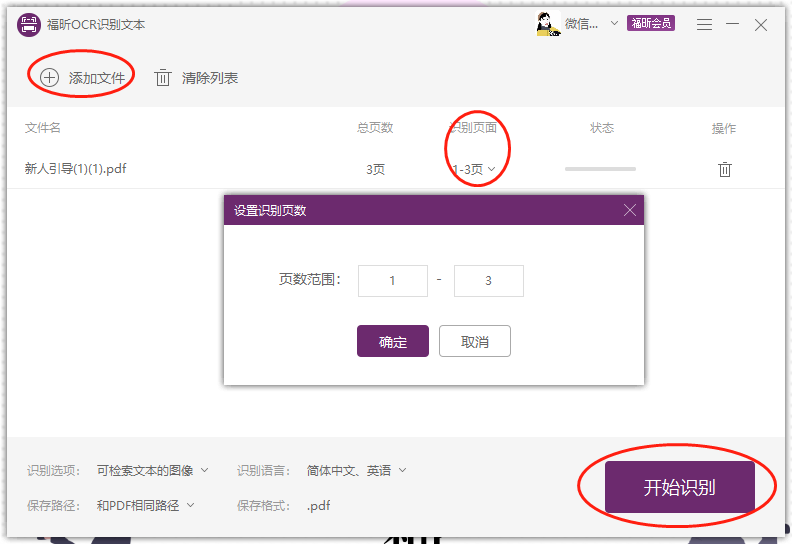
3、最后我们要找到弹窗中的【添加文件】按钮,根据自己想要OCR文字识别的PDF设置识别的页面范围,最后点击【开始识别】即可。
MAC版PDF编辑器的PDF OCR文字识别的操作就在上文,还不动起手试试吗?
版权声明:除非特别标注,否则均为本站原创文章,转载时请以链接形式注明文章出处。
政企
合作

了解平台产品

预约产品演示

申请产品试用

定制合作方案
福昕
福利官
扫一扫添加福昕福利官
了解平台产品
预约产品演示
申请产品试用
定制合作方案

添加福昕福利官
微信扫码
免费获取合作方案和报价



