









扫一扫添加福昕福利官

Windows中的PDF扫描文件如何进行文字识别提取呢?电子办公的袭来,让我们在工作中接触到的办公软件已经是家常便饭的事情啦!那么我们今天就来说说三大办公软件之一的PDF办公文件,相信大家都有听过扫描件这三个字了吧,很多的扫面件的保存都是通过PDF文件保存的。首先能PDF文件可以提供稳固的格式,其次是PDF文件的应用较为广泛,如海报,课件等等。现在有一个问题,因为海报中的文案要进行提取,可以海报往往保存于PDF文件中都是以图片格式存入的,现在进行转换格式了,导出的却还是图片,那么我们要怎么进行文案提取呢?小编来告诉你们一个关于图片文字提取的小技术,那就是PDF文件OCR文字识别,下面小编就带你们好好学习一下这个PDF编辑妙招!

工具准备:【福昕PDF编辑器】
1、首先大家在本站下载【福昕PDF编辑器】,完成安装后打开,把需要进行OCR文字识别的PDF文件准备好,然后导入。
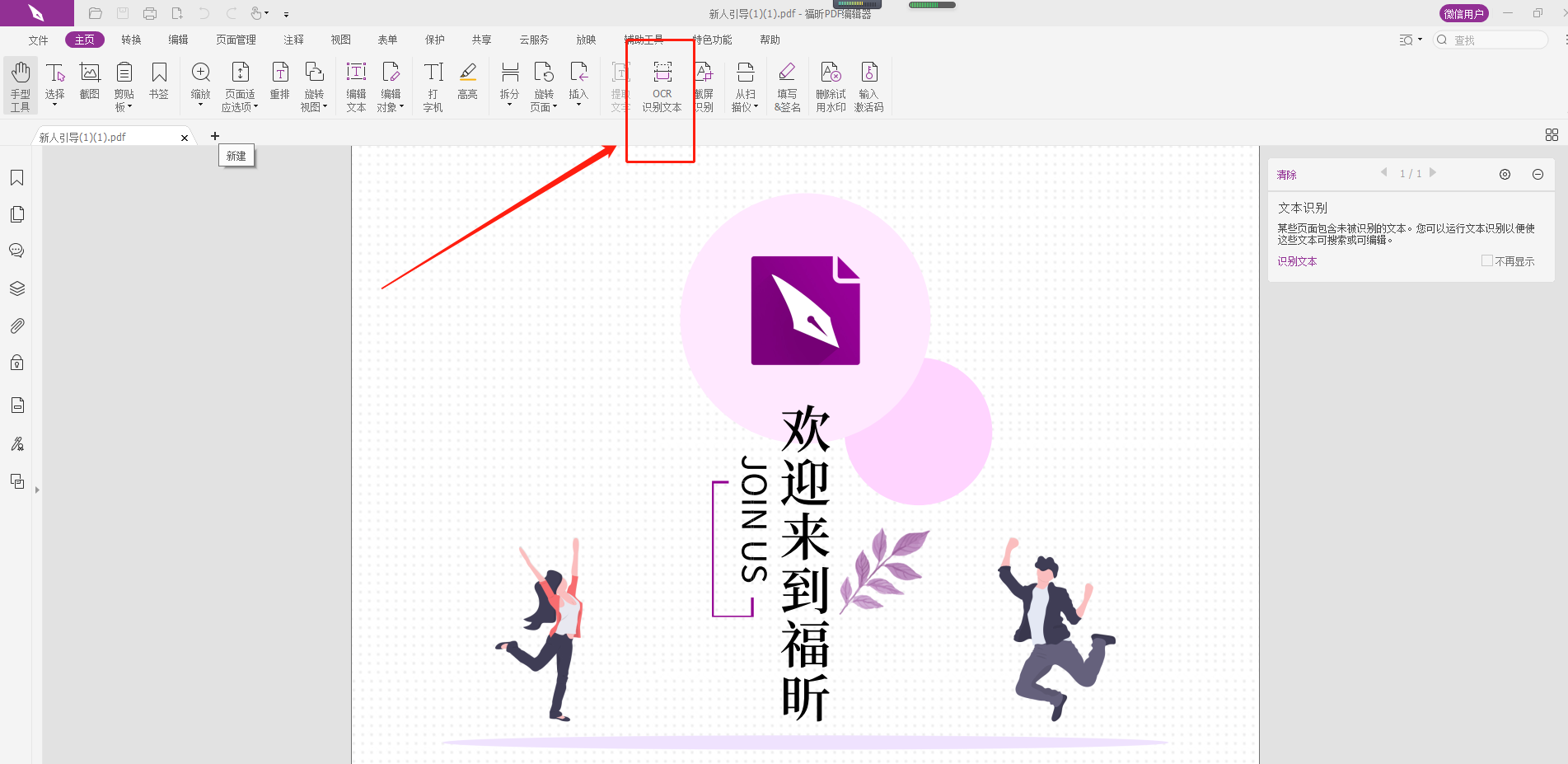
2、完成第一步之后,我们找到顶部的【OCR文字识别】功能。
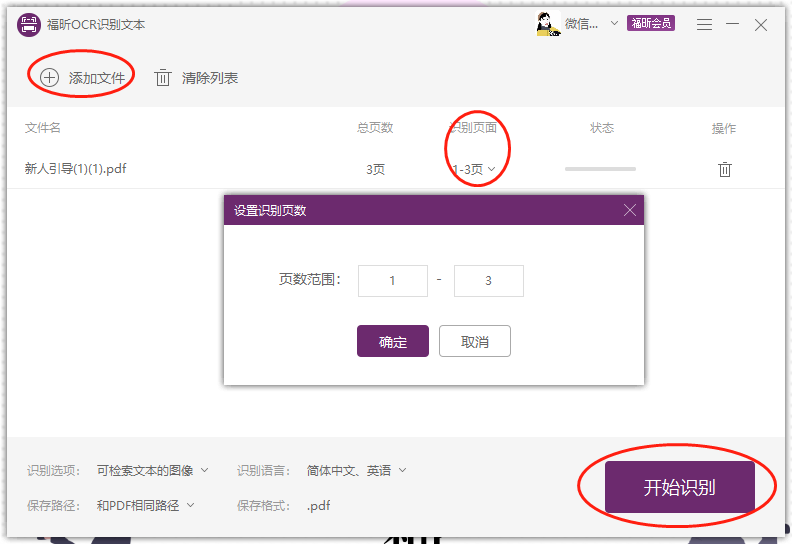
3、最后我们要找到弹窗中的【添加文件】按钮,根据自己想要OCR文字识别的PDF设置识别的页面范围,最后点击【开始识别】即可。
以上就是今天小编给你们分享的MAC小技巧啦!轻松实现PDFOCR文字识别的操作流程啦!
版权声明:除非特别标注,否则均为本站原创文章,转载时请以链接形式注明文章出处。
政企
合作

了解平台产品

预约产品演示

申请产品试用

定制合作方案
福昕
福利官
扫一扫添加福昕福利官
了解平台产品
预约产品演示
申请产品试用
定制合作方案

添加福昕福利官
微信扫码
免费获取合作方案和报价



